Start¶
Model Framework¶
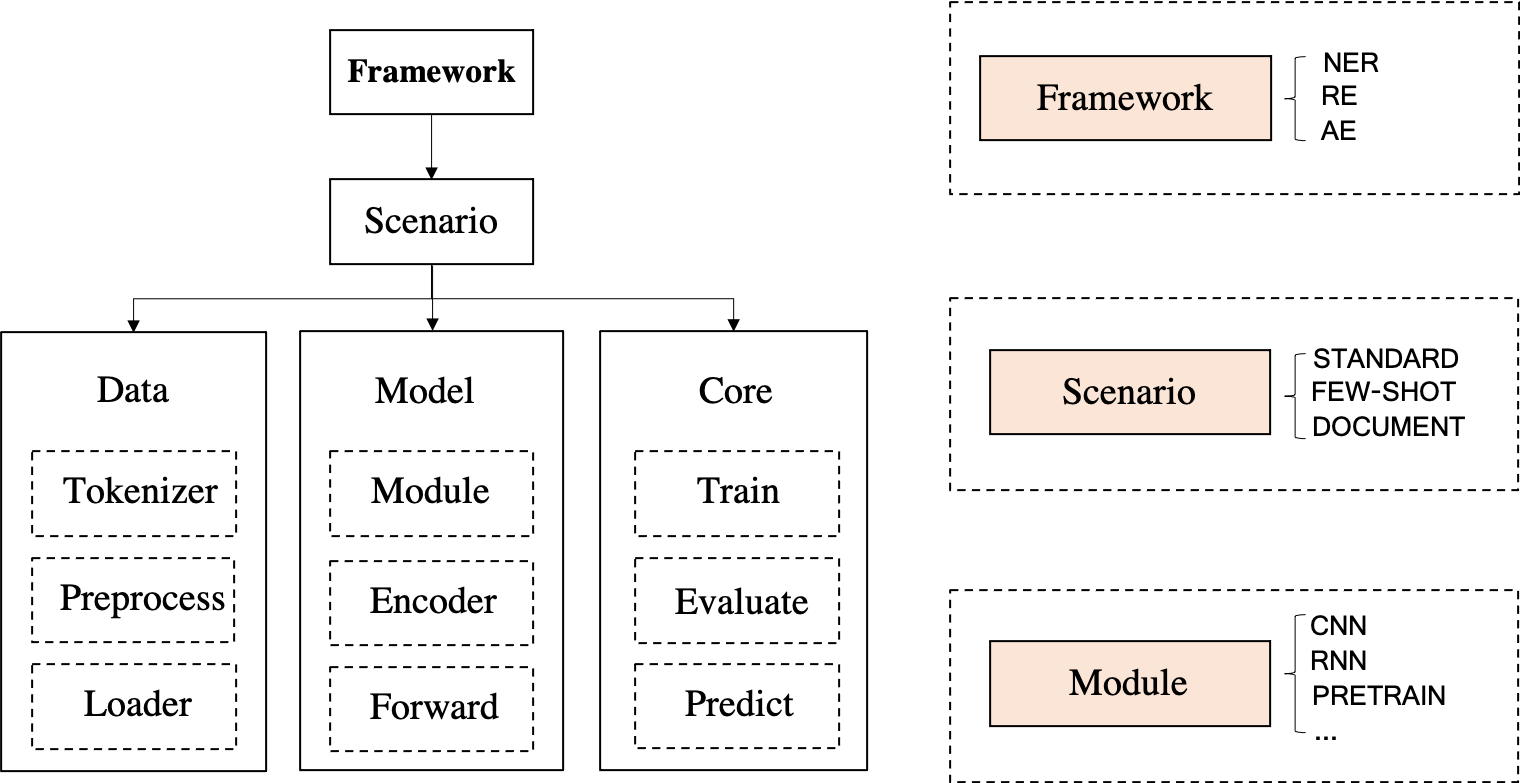
DeepKE contains three modules for named entity recognition, relation extraction and attribute extraction, the three tasks respectively.
Each module has its own submodules. For example, there are standard, few-shot, document-level and multimodal submodules in the relation extraction modular.
Each submodule compose of three parts: a collection of tools, which can function as tokenizer, dataloader, preprocessor and the like, a encoder and a part for training and prediction.
Dataset¶
We use the following datasets in our experiments:
Task |
Settings |
Corpus |
Language |
Model |
|---|---|---|---|---|
Name Entity Recognition |
Standard |
CoNLL-2003 |
English |
BERT |
People’s Daily |
Chinese |
|||
Few-shot |
CoNLL-2003 |
English |
LightNER |
|
MIT Movie |
||||
MIT Restaurant |
||||
ATIS |
||||
Multimodal |
Twitter15 |
English |
IFAformer |
|
Twitter17 |
||||
Relation Extraction |
Standard |
DuIE |
Chinese |
CNN |
RNN |
||||
Capsule |
||||
GCN |
||||
Transformer |
||||
BERT |
||||
Few-shot |
SEMEVAL(8-shot) |
English |
KnowPrompt |
|
SEMEVAL(16-shot) |
||||
SEMEVAL(32-shot) |
||||
SEMEVAL(Full) |
||||
Document |
DocRED |
English |
DocuNet |
|
CDR |
||||
GDA |
||||
Multimodal |
MNRE |
English |
IFAformer |
|
Attribute Extraction |
Standard |
Triplet Extraction Dataset |
Chinese |
CNN |
RNN |
||||
Capsule |
||||
GCN |
||||
Transformer |
||||
BERT |
Get Start¶
If you want to use our code , you can do as follow:
git clone https://github.com/zjunlp/DeepKE.git
cd DeepKE