
Language agents have achieved considerable performance on various complex tasks. Despite the incessant exploration in this field, existing language agent systems still struggle with costly, non-reproducible data reliance and face the challenge of compelling a single model for multiple functions. To this end, we introduce AutoAct, an automatic agent learning framework that does not rely on large-scale annotated data and synthetic trajectories from closed-source models (e.g., GPT-4). Given limited data with a tool library, AutoAct first automatically synthesizes planning trajectories without any assistance from humans or strong closed-source models. Then, AutoAct leverages a division-of-labor strategy to automatically differentiate based on the target task information and synthesized trajectories, producing a sub-agent group to complete the task. We conduct comprehensive experiments with different LLMs, which demonstrates that AutoAct yields better or parallel performance compared to various strong baselines.
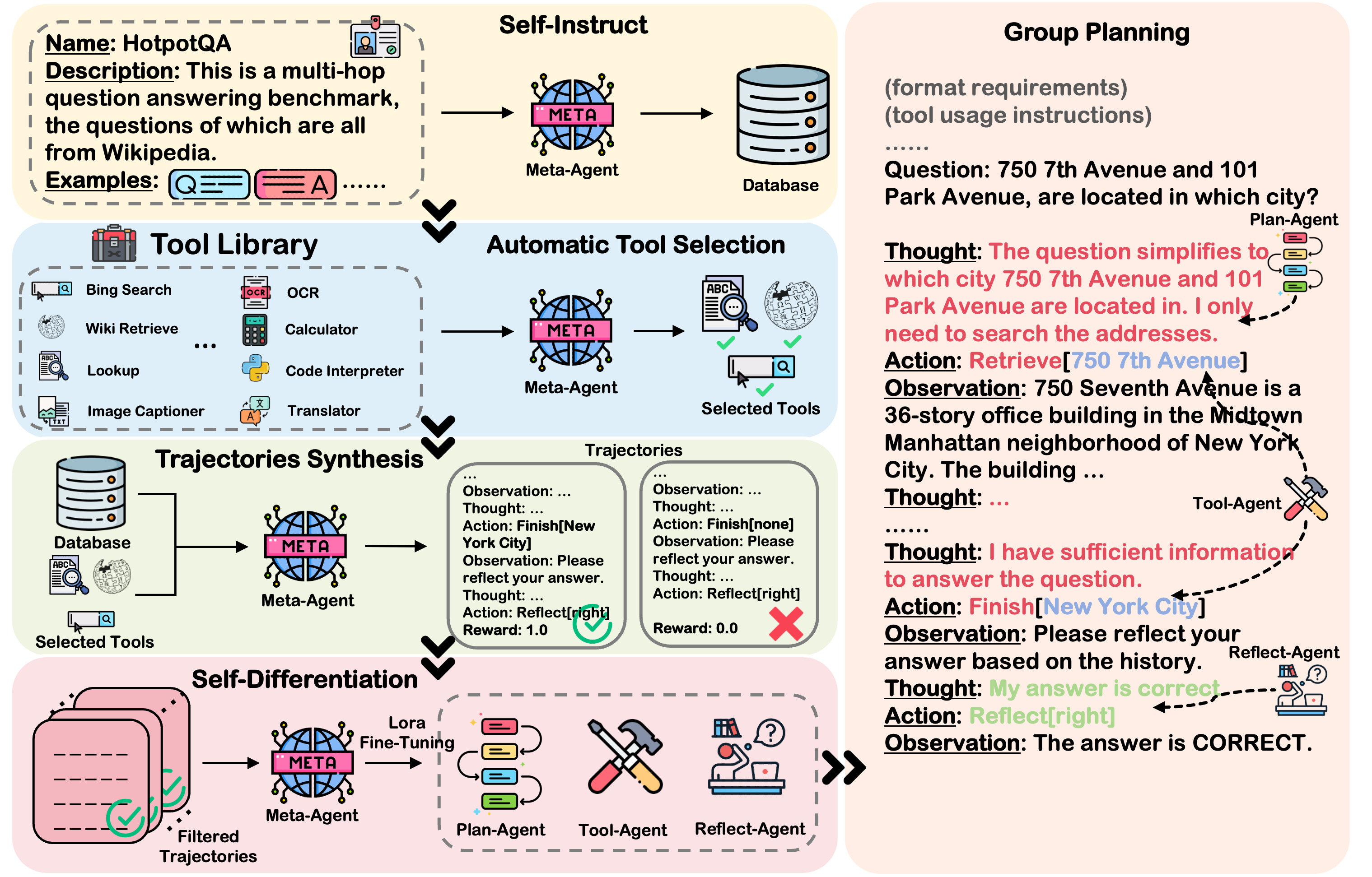
Figure 1: The overview of our proposed framework AutoAct.
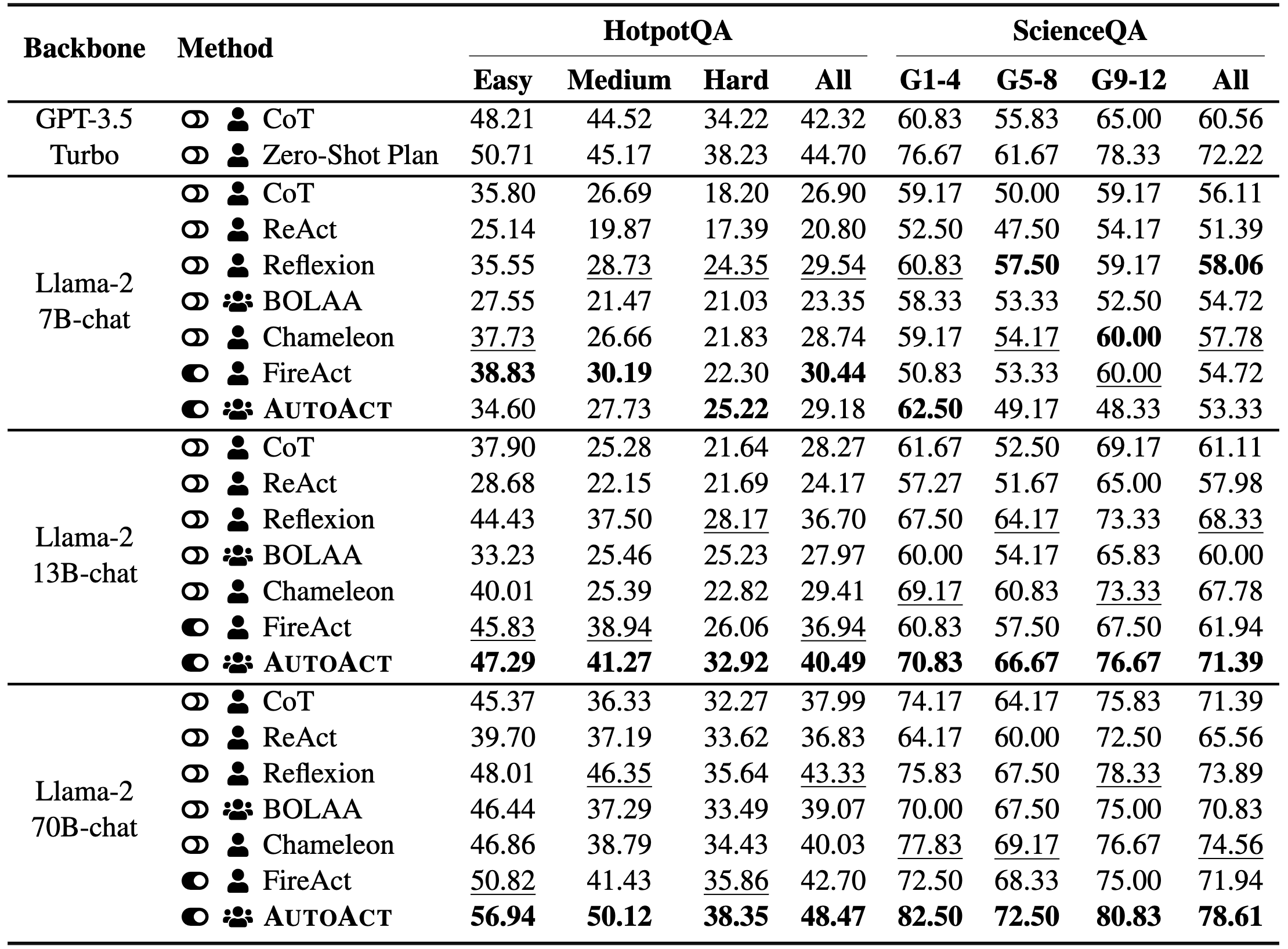
Table 1: Main results of AutoAct compared to various baselines on HotpotQA and ScienceQA. The icon indicates prompt-based agent learning without fine-tuning, while means fine-tuning-based agent learning. denotes single-agent learning and symbolizes multi-agent learning. The best results of each model are marked in bold and the second-best results are marked with underline.

Table 2: Approach ablations of AutoAct. - reflection symbolizes removing the reflect-agent in AutoAct. - multi denotes feeding all the differentiated data into one model for fine-tuning. - fine-tuning indicates zero-shot prompt planning with the three agents defined in AutoAct. - filtering represents self-differentiation on all the trajectories generated in zero-shot planning without filtering wrong cases.
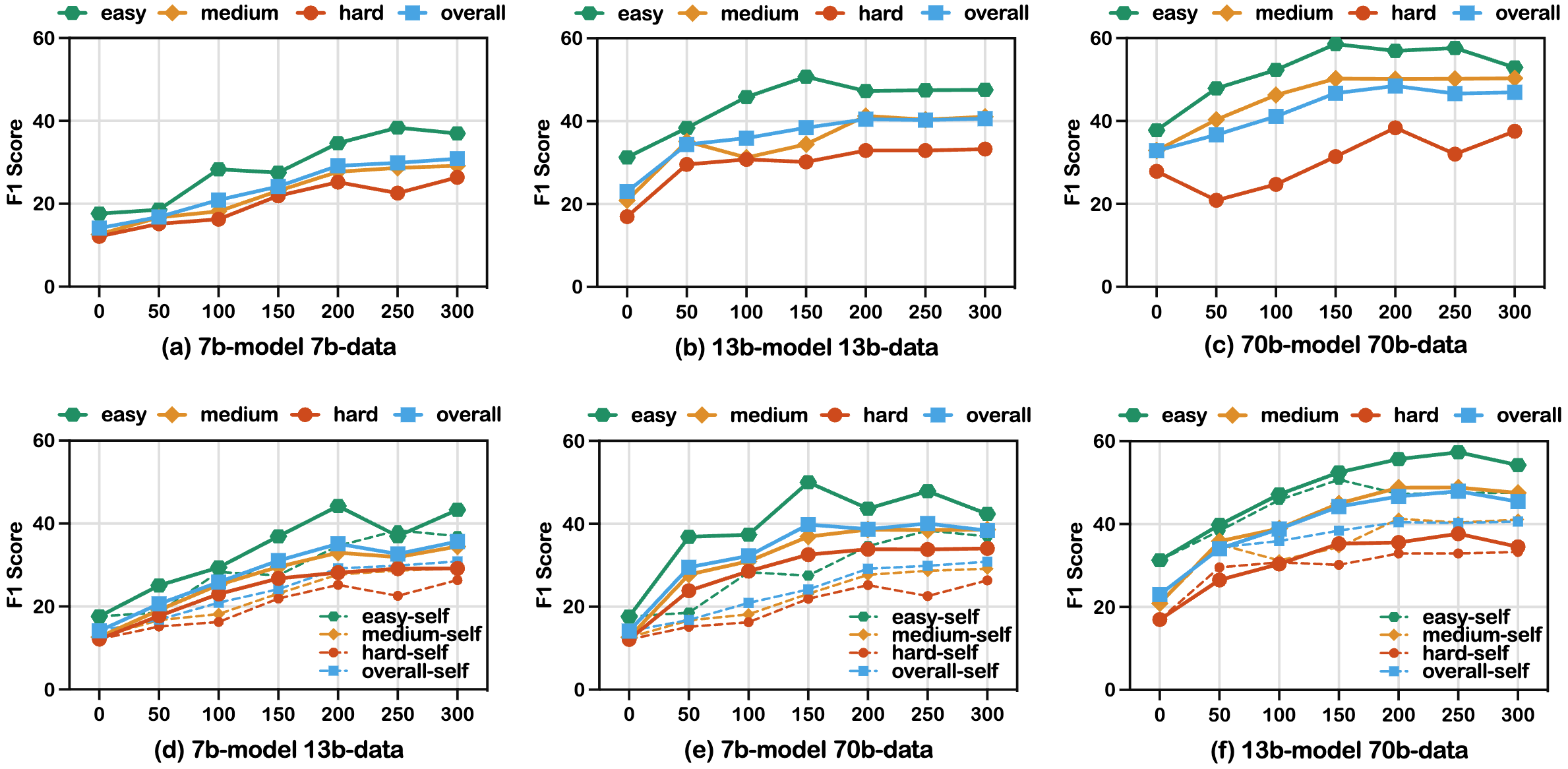
Figure 2: Performance of AutoAct on different training data scales. (a-c) represents the results of the model trained on self-synthesized trajectories. (d-f) represents the results of the model trained on trajectories synthesized by a stronger model, where the dashed line is the baseline trained on self-synthesized trajectories.

Figure 3: Performance of AutoAct based on different degrees of labor division. One is training a single model with all the differentiated data. Three represents the differentiation into three agents: plan, tool, and reflect. Tool Specified indicates further differentiating the tool-agent with one tool, one agent.
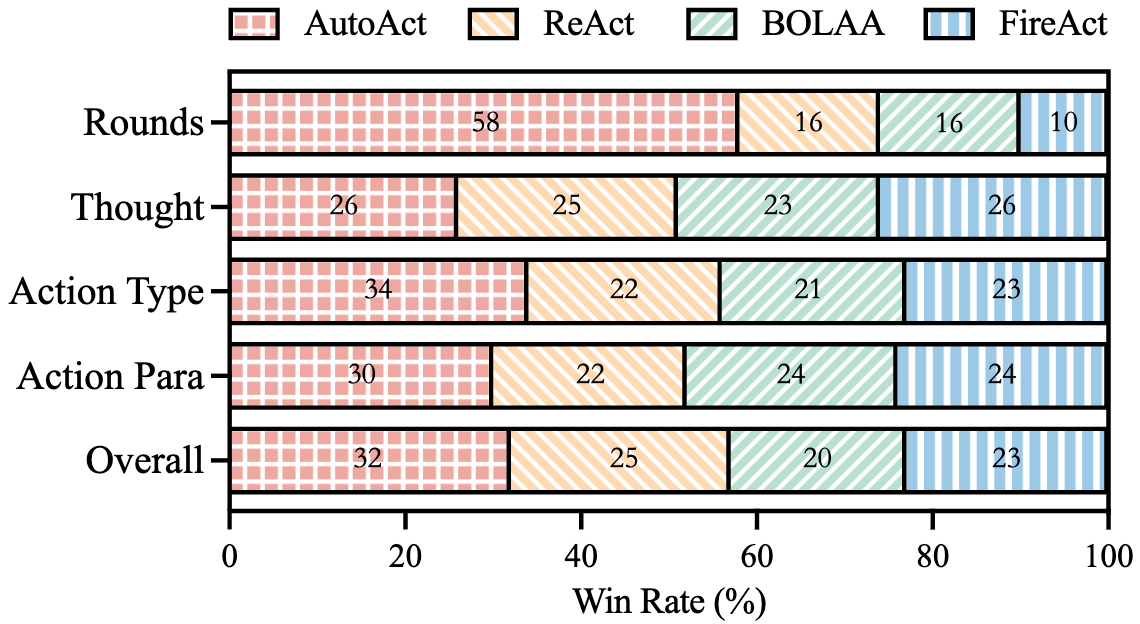
Figure 4: Human evaluation of trajectories generated by Llama-2-70b-chat on HotpotQA. We compare the number of planning rounds, the logical correctness of thoughts, action types, action parameters, and the overall coherence of each trajectory.
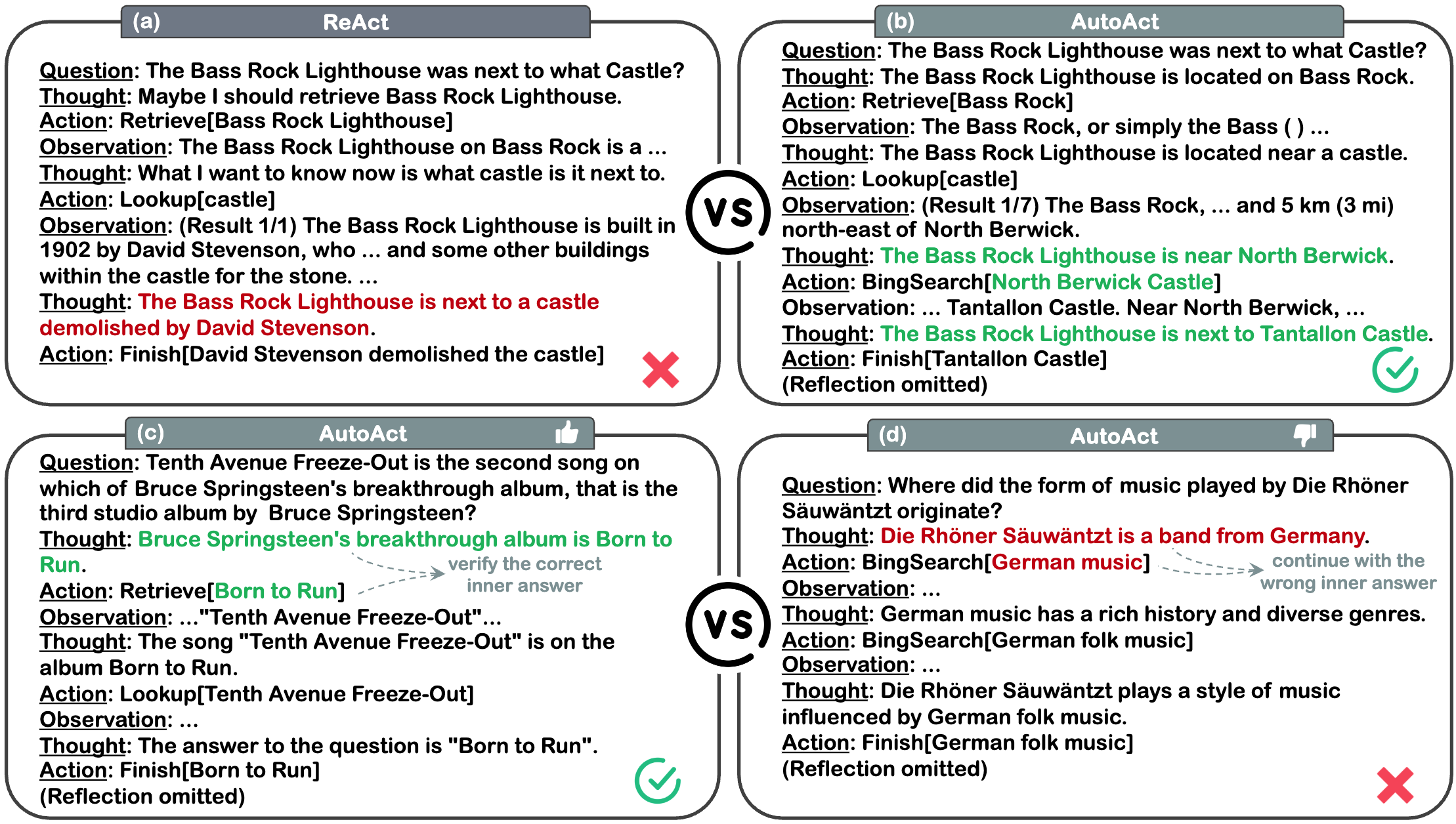
Figure 5: Case study. AutoAct (b) successfully addresses the failure in ReAct (a) by employing a more scientific combination of tools and making more accurate tool invocations. With more planning rounds, AutoAct (c) can validate its inner answers by continuing more rounds of self-verification. While this can also lead to a longer context, gradually deviating AutoAct (d) from the original question.
@article{qiao2024autoact,
author = {Shuofei Qiao and Ningyu Zhang and Runnan Fang and Yujie Luo and Wangchunshu Zhou and Yuchen Eleanor Jiang and Chengfei Lv and Huajun Chen},
title = {AutoAct: Automatic Agent Learning from Scratch via Self-Planning},
journal = {CoRR},
year = {2024},
eprinttype = {arXiv},
eprint = {2401.05268},
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.