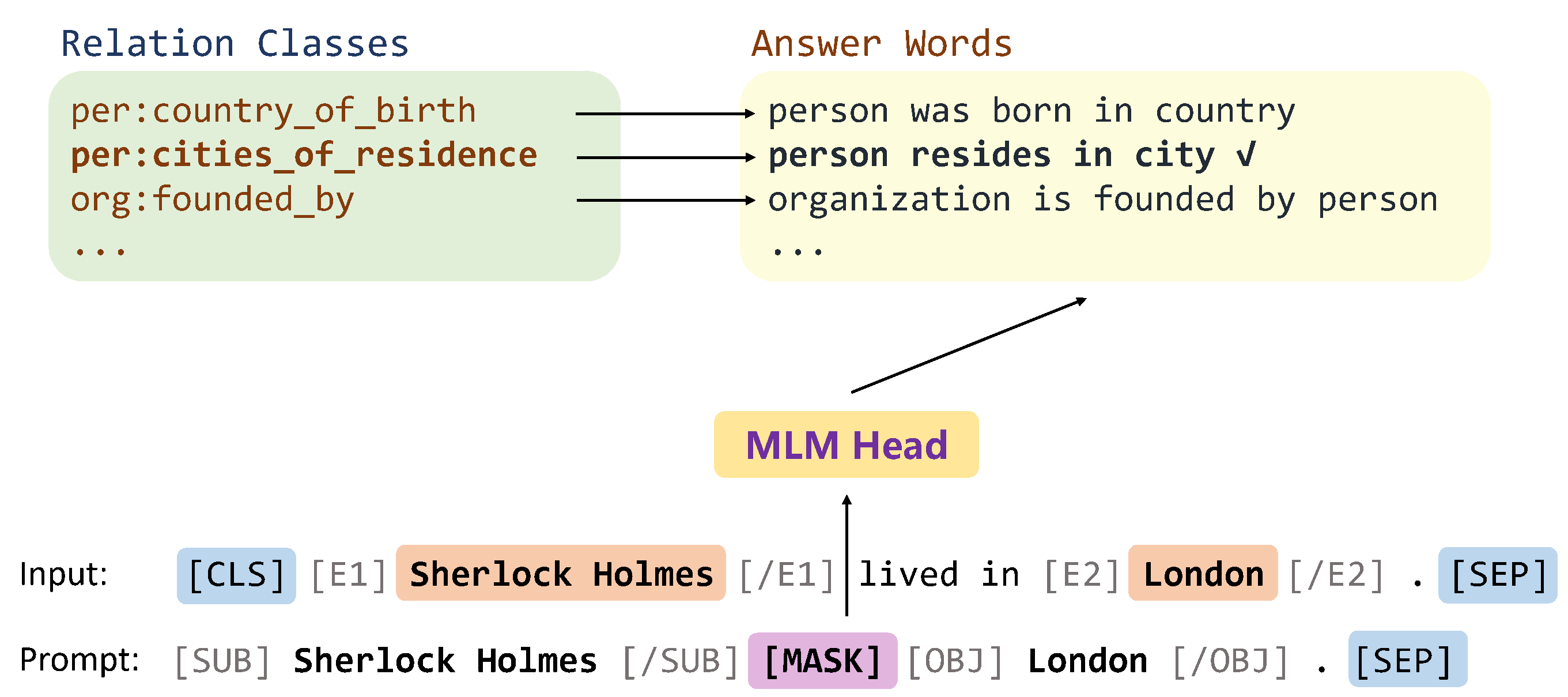
Meet Low-resource RE!
An Empirical Benchmark for Low-resource Relation Extraction.
An Empirical Benchmark for Low-resource Relation Extraction.
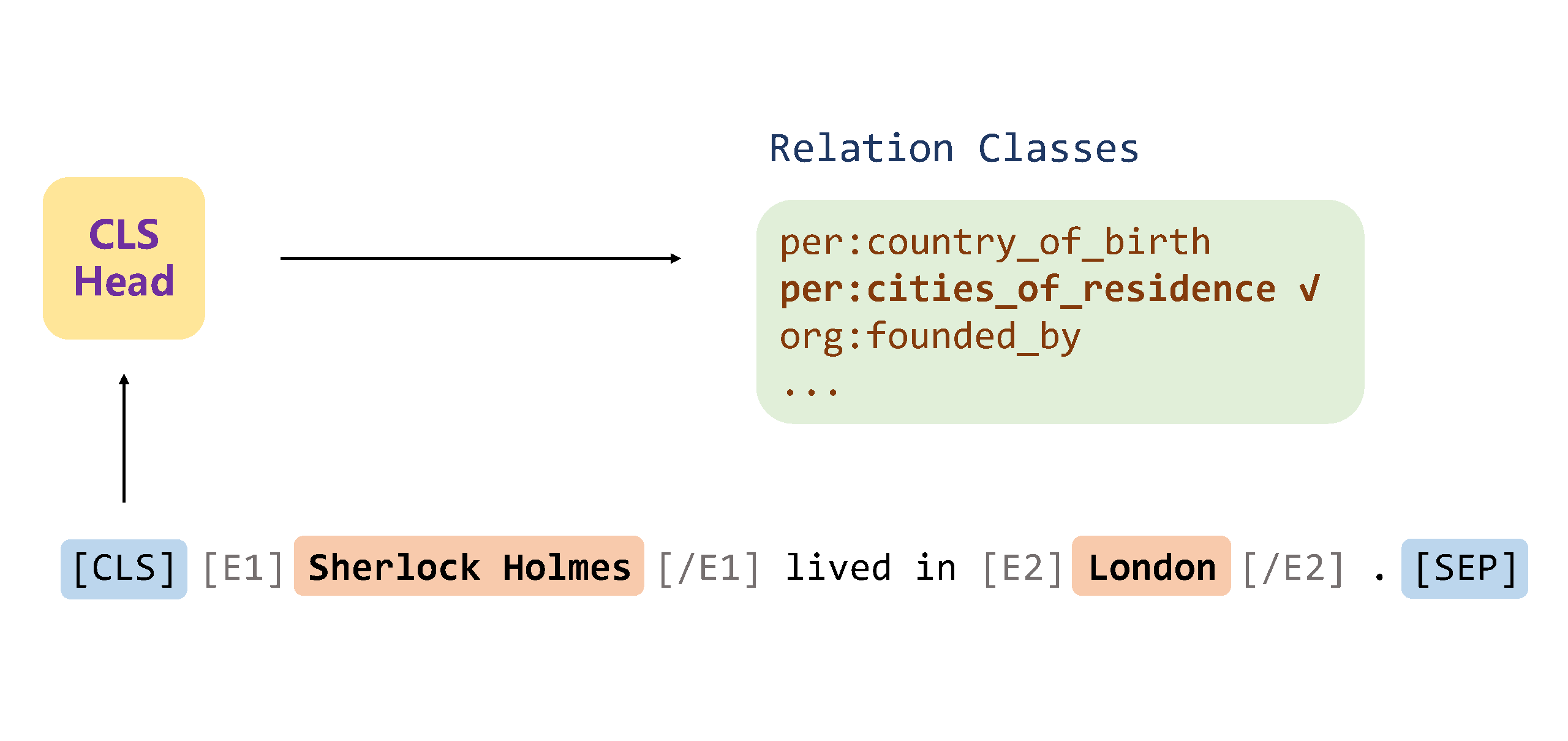
Supervised Pre-trained Models Fine-tuning with strong baselines, such as OpenNRE.

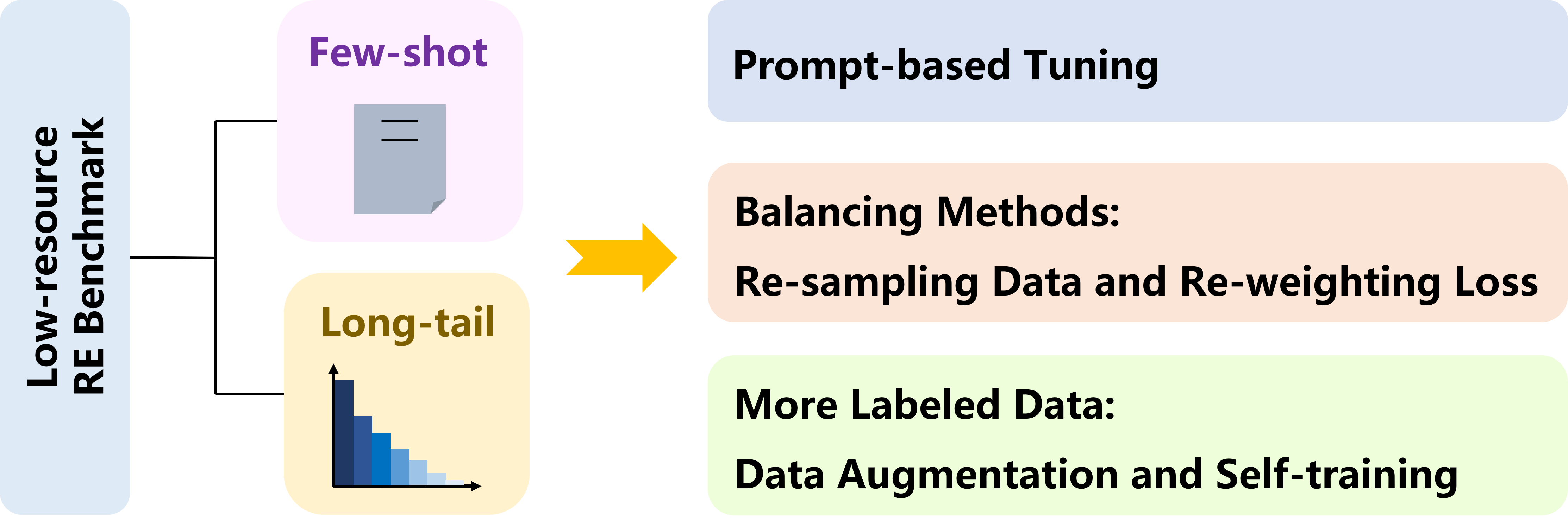
Re-sampling Methods and Re-weighting Losses for
Long-tailed Distribution Issues.
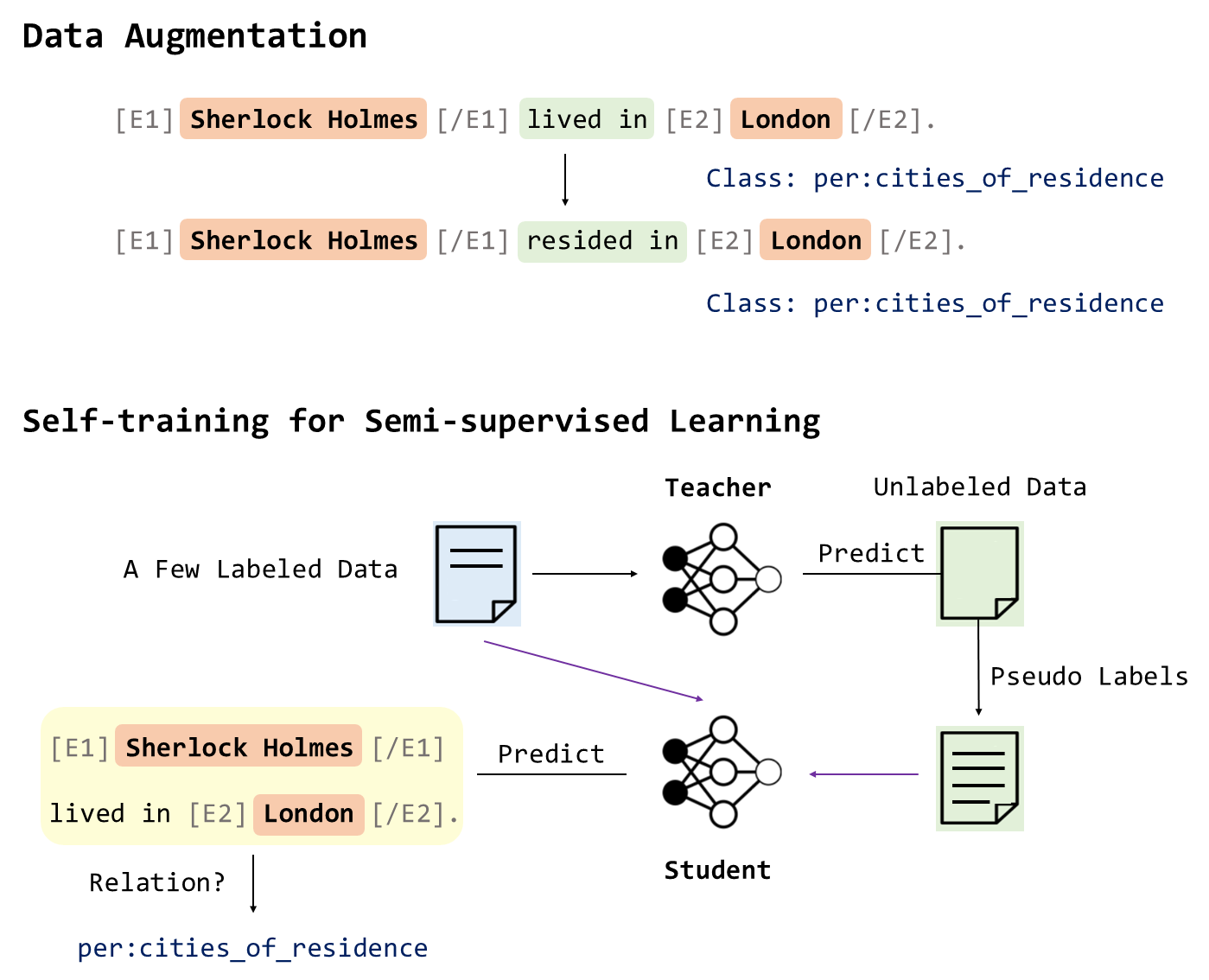
Diverse Data Augmentation Methods and Self-training
to Generate More Labeled Data
from Easy-collected Unlabeled Data.
The Low-resource Relation Extraciton benchmark is a comprehensively empirical study on low-resource RE. It focuses on two challenges:
We hope this study can help inspire future research for low-resource RE with more robust models and promote transitioning the technology to real-world industrial scenarios.

@article{LREBench2022,
title={Towards Realistic Low-resource Relation Extraction: A Benchmark with Empirical Baseline Study},
author={Xin Xu, Xiang Chen, Ningyu Zhang, Xin Xie, Xi Chen, Huajun Chen},
journal={EMNLP},
year={2022}
}